
文系の受験者も多いG検定の過去問の概略についてまとめています。
(参考記事:G検定の過去問対策「シラバス」:人工知能の動向と問題について)
ここでは、G検定のシラバス:「機械学習の具体的手法」について解説します。
機械学習とは、人間が自然に兼ね備える学習能力と同じ機能を人工知能(AI)で実現させる手法や技術のことです。
この機械の学習能力は、AI(人工知能)が実用化まで飛躍的に進歩した鍵になります。
AIを使いこなすためには「機械で何ができるか?」を知っておく事は重要です。
本文では、G検定の公式テキストの内容を中心に、要点をまとめていきます。

機械学習の3つの種類
機械学習は、何でも出来ると錯覚されがちですが、得意不得意分野があります。
目的に合わせて使い分けると、よりAIは能力を発揮します。
3つの分野に分かれます。
・教師あり学習
・教師なし学習
・強化学習
ここで使われる「教師」とは、出力データのことです。
教師あり学習
教師あり学習とは、予め判断基準になるデータがあることです。
【与えられたデータ(入力を元に、そのデータがどんなパターン(出力)になるかを識別・予測する】
・過去の売上げから、将来の売上を予測したい(数字)
・与えられた動物の画像が、何の動物かを識別したい(カテゴリー)
「売上予測」は、連続する値、「動物の画像」はカテゴリーと2種類の予測があります。
数字など連続する値を予測する問題を回帰問題。
カテゴリーなど離散値を予測する問題を分類問題と呼びます。
また、Googleの機械翻訳なども「教師あり学習」です。
【英語に対応する日本ごのパターンを予測する】
・英文を日本語訳に翻訳する。
英語の機械翻訳は、通訳や翻訳者だけでなく、グローバル社会では最も不可欠になりそうな技術です。
(参考記事:AI(人工知能)の自動翻訳サービスを検証!AI時代に英語力は無駄になるのか?)
教師なし学習
教師なし学習とは、(入力)データそのものが持つ構造・特徴が対象です。
・ECサイトの売上データから、どういった顧客層があるのかを認識したい。
・入力データの各項目間にある関係性を把握したい。
教師なし学習と教師あり学習は、使える用途が異なります。
教師あり学習の代表的な手法
G検定では、機械学習を具体的に使う手法についても出題されます。
プログラミングをしない文系であっても、各手法が持つデータの扱い方や応用特質の理解は、必要です。
文系にとって難解な用語は、最初から全部を理解しようとするのは無理なので、大まかに捉えてください。
線形回帰(linear regression)
統計で用いられる最もシンプルなモデルの1つです。
データ(の分布)であれば直線です。
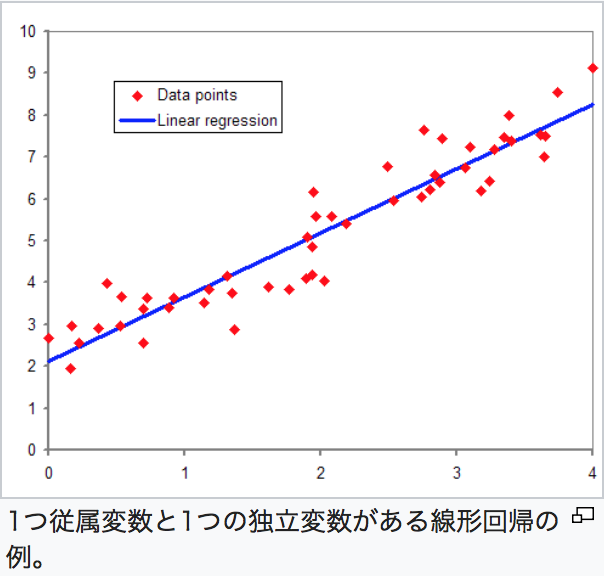
(画像引用:Wikipediaより)
他にも線形回帰に正則化項を加えた手法に、ラッソ回帰(lasso regression)、リッジ回帰(ridge regression)があります。
正則化(せいそくか、英: regularization)とは、
数学・統計学において、特に機械学習と逆問題でよく使われるが、機械学習で過学習を防いだり、逆問題での不良設定問題を解くために、追加の項を導入する手法である。
(引用:Wikipediaより)
簡単に言えば、機械学習の過剰な学習を防ぎ適正化する役割があるようです。
ラッソ回帰とリッジ回帰の説明は、ここでは省きます。
ロジスティック回帰(logistic regression)
上記の回帰問題の分類問題版が、ロジスティック回帰(logistic regression)です。
モデルの出力にシグモイド関数を使います。

(引用:Wikipediaより)
ランダムフォレスト(random forest)
決定木(decision tree)を用いる手法です。
決定木とは、様々な分岐路から最終的に1つのパターンを予測する分岐路のことです。
木構造にする事により、意思決定を助けることを目的としています。
例えば、下記はゴルフ場の来場者状況が、天気によって左右されるを分析した決定木です。
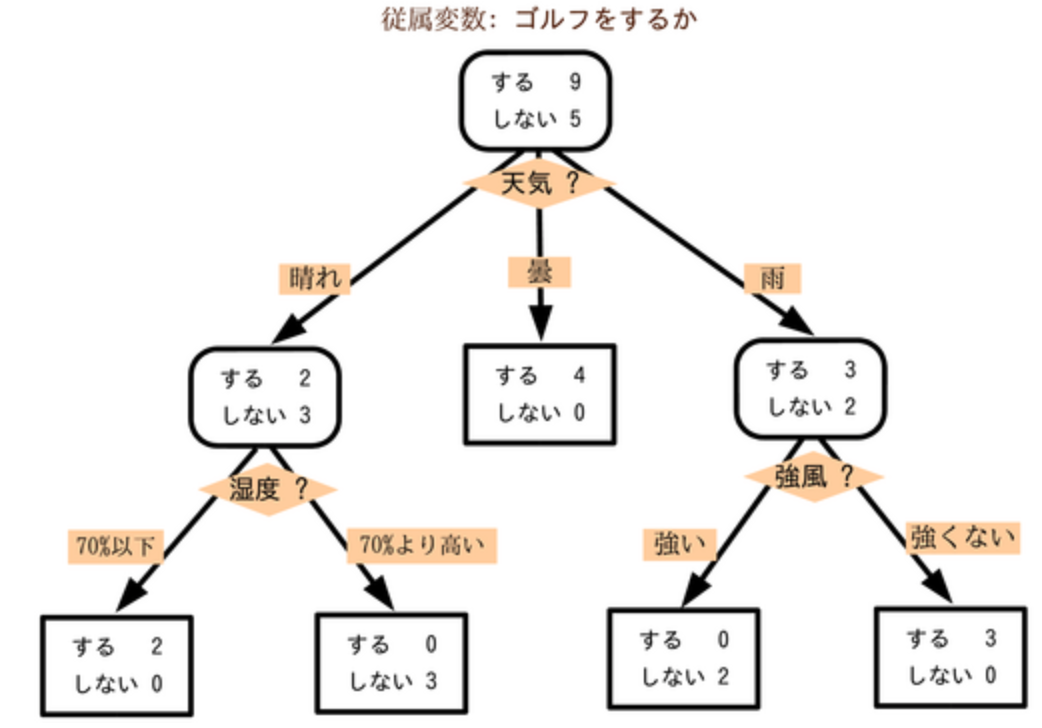
(引用画像:Wikipediaより)
決定木には2つの呼び名があります。
・回帰木 (regression tree)
・分類木 (classification tree)
数値の予測(回帰モデルの作成)をする場合は回帰木を使い、分類(分類モデルの作成)のときは、分類木を使います。
ランダムに特徴量を選び決定木を作る
教師あり学習は、複数の特徴量(入力)をもとにパターンを出力します。
どの特徴量がどんな値になるかを順々に考え、データが複雑になればなる程、複数の組み合わせが考えられます。
ランダムに特徴量を選び、複数の決定木が作られます。
ランダムフォレストとアンサンブル学習
ランダムフォレストとは、それぞれ結果を用いて多数決を取ることです。
このように複数のモデルで学習させることをアンサンブル学習と言います。
多数決により様々な結果を融合させ、予測能力を向上させるための学習です。
厳密に区分すると、全部から一部のデータを用いて複数のモデルを学習する手法をバギングと言います。
これは情報を全部使わずに、一部を使用し学習することで、最後に結合させていく方法です。
データは、別個で計算する事ができるので、並列処理が可能になります。
ブースティング(boosting)
ブースティングもバギングと同様に、一部のデータを繰り返し抽出し、複数のモデルを学習させます。
バギングとの違いは、データの作成方法です。
・複数のモデルを一気に並列に作成(バギング)
・逐次的に作成(ブースティング)
ブースティングも、モデル部分では決定木が用いられています。
ランダムフォレストよりも、逐次的に学習を進めていくブースティングの方が良い精度が得られます。
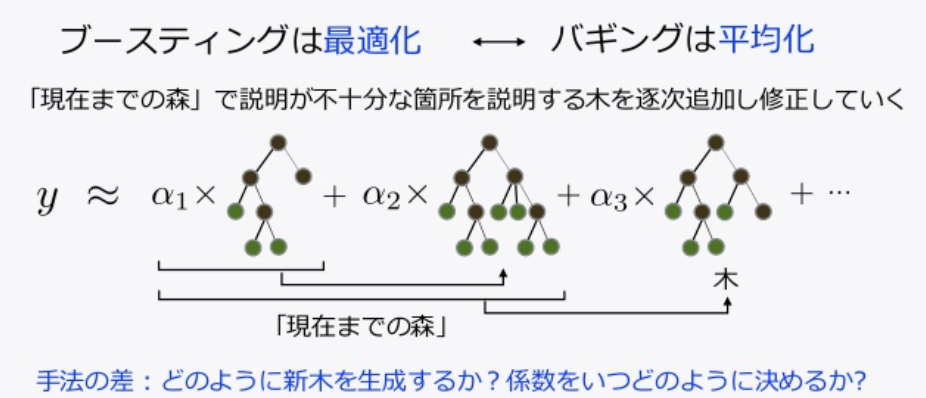
(引用画像:slideshareより)
サポートベクターマシン
SVM(Support Vector Machine)と呼ばれ、ディープラーニングの使用前は、最も人気のあった機械学習の手法です。
各データ点との距離が最大となるような境界線を求めることで、パターン分類を行います。
この距離を最大化する事をマージン最大化と言います。
マージン最大化とは、下図のように、赤と青のグループ間の最も距離の離れた箇所(最大マージン)を緑と黄線で出し、その真ん中に識別の線を引くことです。

(引用画像:サポートベクターマシン(SMV)より)
マージンを最大化する理由は、広い幅をとる方が、新たにデータが観測された場合に、より上手く分類できるからです
しかし、この手法は問題もあります。
・扱うデータは高次元
・データが線形分類できない(直線で分類できない)
問題を解決するために、形で分離ができないデータを、非線形な基底関数で表現し直し、高次元に写像します。
そして、その写像後の空間で線形を分類するアプローチが取られました。
この写像に用いられる関数をカーネル関数、実際に写像する手法は、カーネルトリック(kernel trick)と呼びます。
下記の動画を見るとイメージがわかります。
「Performing nonlinear classification via linear separation in higher dimensional space」
(参照:Rで学ぶベイズ統計学より)
ニューラルネットワーク
ニューラルネットワーク(neural network)は、人間の脳の中の構造を模したアルゴリズムで、脳機能のいくつかの特性に類似した数理的モデルです。
ディープラーニングの登場で、一躍人気の手法になりました。
人間の脳には、ニューロンと呼ばれる神経細胞が何十億と張り巡らされ、お互いが結びつくことで神経回路を形成しています。
ニューラルネットワークは、人間の脳に限りなく近い状態でパターン認識できる手法です。
単純なニューラルネットワークのモデルは、単純パーセプトロン(simple perceptron)と呼ばれます。
入力を受け取る部分を入力層、出力する部分を出力層と表現します。
更に層を追加した複雑なモデルは、多層パーセプトロン(multilayer perception)です。
【多層パーセプトロンの模式図】
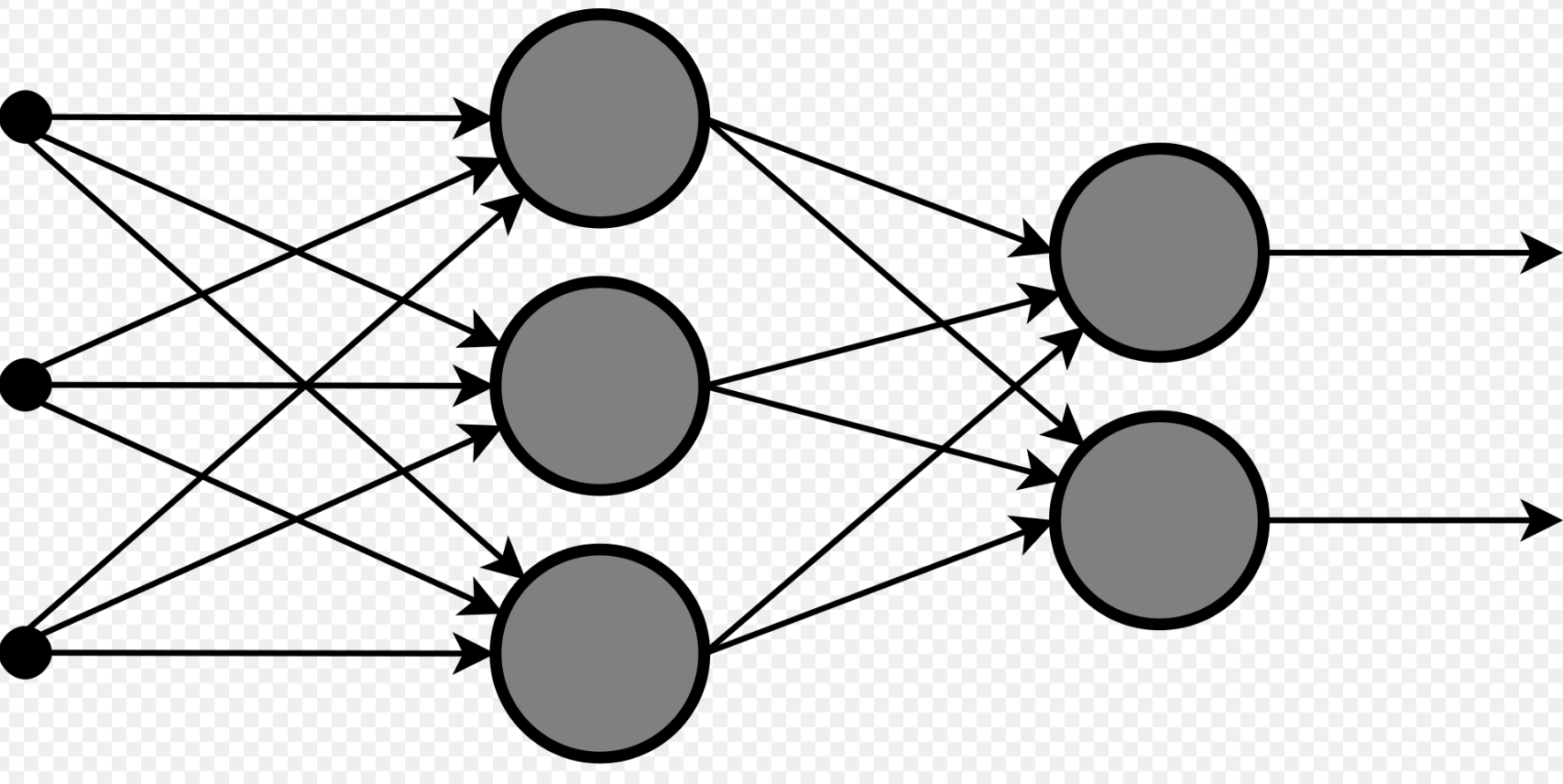
(引用:Wikipediaより)
入力層と出力層の間に追加された層を隠れ層と言い、この隠れ層の追加により、ネットワーク全体の表現力は大きく向上します。
この多層パーセプトロンでは、非線形分類も行うことも可能です。
また、層が増えると調整すべきデータ数も増えますが、それを調整するアルゴリズムが誤差逆伝播法(backpropagation)です。
予測値と実際の値との誤差をネットワークにフィードバックすることで、効率的なアルゴリズムを実現します。
教師なし学習の代表的な手法
教師なし学習とは、データの背後に存在する本質的な構造を抽出するために用いられ、「まとめる」「分析」の手法が主になります。
ここでは、教師なし学習の代表的な手法「K−平均法」や「主成分分析」を紹介します。
K-平均法(K-means)
この手法は、元のデータからグループ構造を見つけ出し、それぞれをまとめ、データをK個のグループに分けることを目的にします。
このk個のkは、自分で設定する値になります。
このグループのことをクラスタ(cluster)、k-meanを用いた分析のことをクラスタ分析と呼びます。
クラスタ分析には2種類あります。
・階層クラスター分析
・非階層クラスター分析
図でみると違いがわかりやすいです。
下図は、寿司ネタの選好度データから、寿司ネタを分類するために階層クラスター分析を行った結果です。
【階層クラスター分析】
樹形図のクラスター分析で寿司ネタの好みを表示しました。
対象をクラスターに分類すると、クラスターが結合されていく過程を直ぐに確認することができます
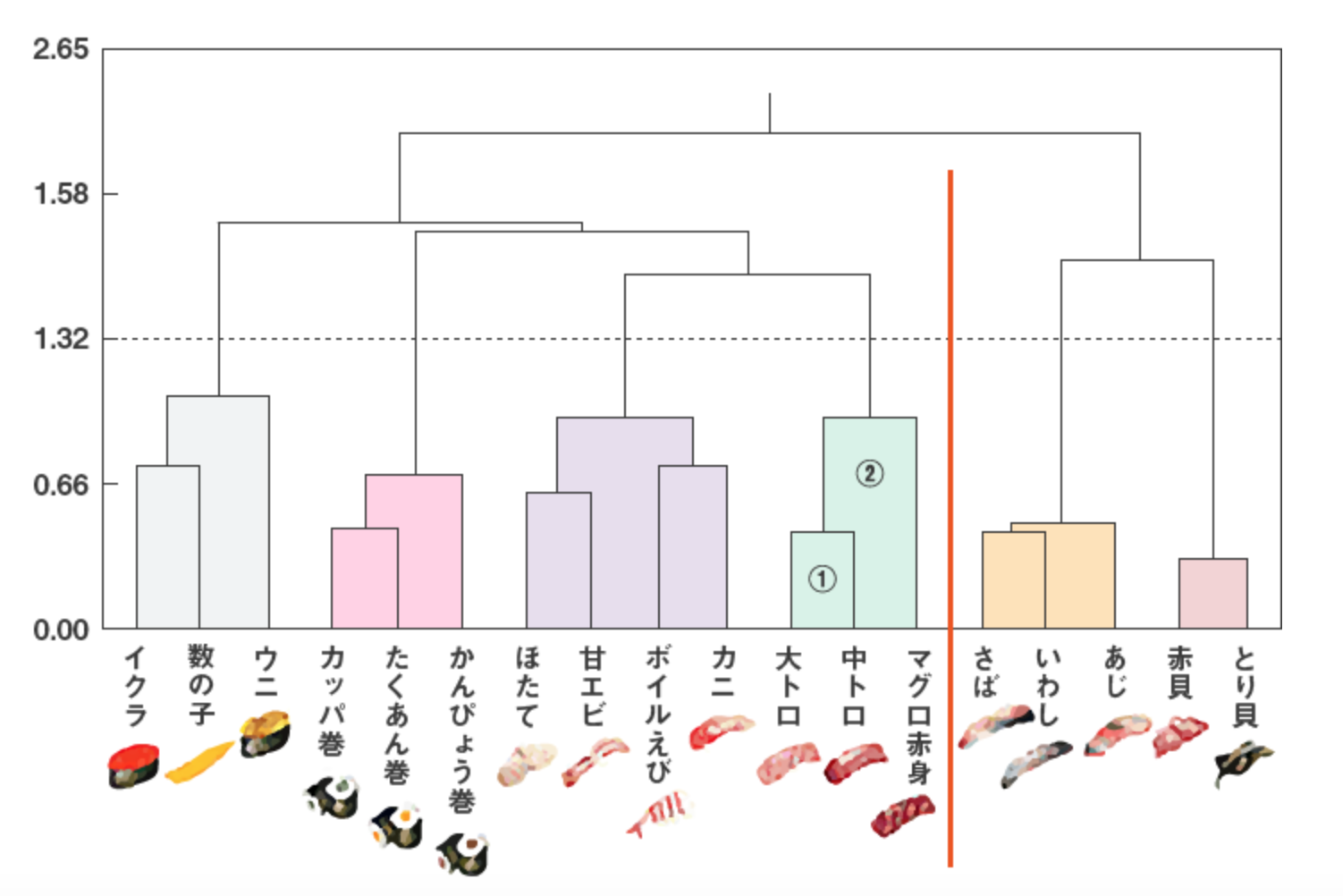
(画像引用:macromillより)
【非階層クラスター分析】
非階層クラスター分析によってアンケート回答者を5つのクラスターに分類した結果です。
寿司ネタの選好データから、人の好みをネタの種類で分類しました。
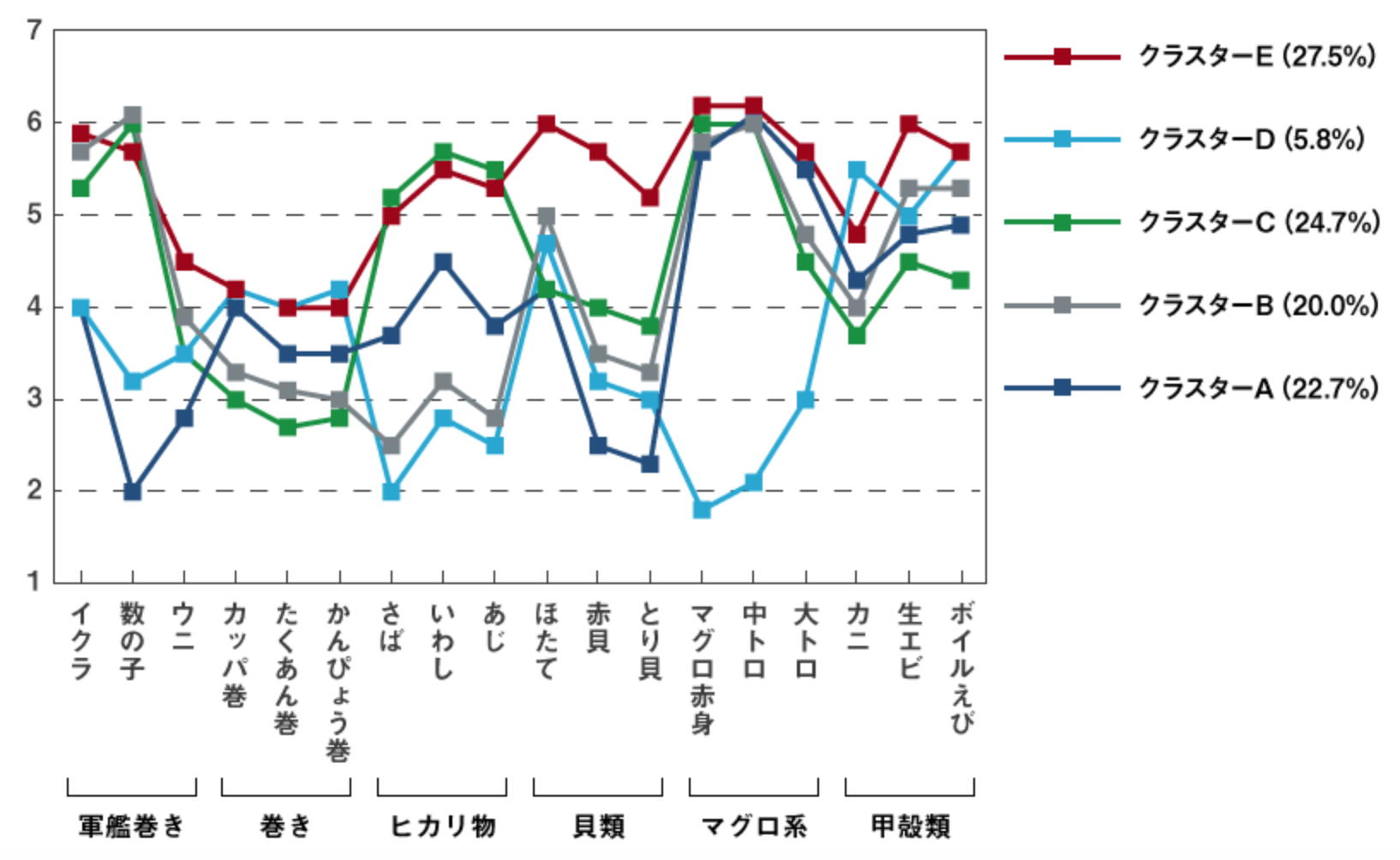
(画像引用:macromillより)
非階層クラスター分析は、多くのデータを扱う処理に向いています。
しかし、クラスタ分析で得られた結果を解釈し、どのように使っていくかは人間の作業になります。
主成分分析
主成分分析(Principal Component Analysis PCA)は、特徴量が多い場合に用いられることが多い手法です。
データの特徴量間の関係性、相関を分析してデータの構造をつかみます。
多数の特徴量から、相関のない少数の特徴量へと次元削減する事が主たる目的となります。
次元削減するメリットは、機械学習で多くなりがちな特徴量を減らすことで、学習時間の削減やデータを可視化することができます。
データの要約ができることは、データの特徴をより判断しやすくなります。
まとめ:G検定過去問対策:機械学習の具体的手法
以上、機械学習の代表的な手法「教師あり学習」と「教師なし学習」については、いかがでしたか?
G検定では、各手法の特徴をおさえてください。
【教師あり学習】
・線形回帰・ロジスティック回帰(シグモイド関数)
・ランダムフォレスト(決定木)
・ブースティング
・サポーートベクターマシン(SVM)
・ニューラルネットワーク
【教師なし学習】
・K-平均法(K-means)
・主成分分析
エンジニアでないと、数式の計算などは、なかなか理解しにくいです。
まずは、図や簡単な言葉に置き換えて、手法をイメージから捉えていくと学習が進みます。

